![]()
�γ̽��
һ��ѧϰĿ�꣺
1. �������ֳ����������������������������������������������λ����ƽ�����ȵĻ������
2. ����ͳ��ͼ������Ҷͼ������ͼ��Ƶ�ʷֲ�ֱ��ͼ�����ĺ��弰���Ӧ�á�
3. ������С���˷����������Իع���������ʵ�����⡣
4. �����㷨�Ļ���˼�룬�����㷨�����ֻ����ṹ���������Ȼ���֪ʶ�����Ӧ�á�
�����ص㡢�ѵ㣺
�ص���1. ���������������������������������ͳ��ͼ���ļ�Ӧ�á�
2. �����������֪ʶ�����ʵ�����⡣
3. �����㷨�Ļ���˼�롢���ֻ������ṹ�����Ӧ����
�ѵ㣺1. �㷨���ͼ����ʶ����Ӧ�á�
2. ����ͳ��ͼ������ʵ�����⡣
�������������
�¿α�߿���ͳ��֪ʶ�Ŀ�����Ҫ�dz��������������������塣ͳ��ͼ����������ص�֪ʶ����������Ͷ�Ϊѡ������⣬��Ŀ�ѶȽ�С����ʱҲ�����ͳ������ʽ�ϵ��е����⡣���㷨�Ϳ�ͼ�Ŀ���Ҫ��ܵͣ���Ҫ�������ֻ��������ṹ����������ͻ�����ѡ������⣬��Ŀ�Ѷ����е����¡���ͼ����ʡ�ͳ�ơ����е�֪ʶ������¿α�߿�����ķ�����
֪ʶ����
һ��ͳ�Ƶ��й�֪ʶ
��һ������������
1. �������������һ������ĸ�������ΪN�����ͨ�������ȡ�ķ������г�ȡһ����������ÿ�γ�ȡʱ�������屻�鵽�ĸ�����ȣ��ͳ������ij���Ϊ�����������ʵ�ּ�������������ó�ǩ���������������
2. ϵͳ�������������еĸ����϶�ʱ���ɽ�����ֳɾ���ļ������֣�Ȼ����Ԥ�ȶ����Ĺ���ÿһ���ֳ�ȡ1�����壬�õ�����Ҫ�����������ֳ�������ϵͳ������Ҳ��Ϊ��е��������
ϵͳ�����IJ���ɸ���Ϊ����1���������еĸ����ţ���2���������ı�Ž��зֶΣ���3��ȷ����ʼ�ĸ����ţ���4����ȡ������
3. �ֲ����������֪�����ɲ������Եļ��������ʱ����������ֳɼ����֣�Ȼ���ո�������ռ�ıȽ��г��������ֳ��������ֲ�������������ֳɵĸ����ֽ����㡣
ע����1�����ֳ��������Ĺ�ͬ�㶼�ǵȸ��ʳ�����������������ÿ�����屻��ȡ�ĸ�����ȣ�����������Ϊn������ĸ�����ΪN�����������ַ�������ʱ��ÿһ�����屻�鵽�ĸ��ʶ���![]() ��
��
��2�����ֳ����������Ե��ص㡢���÷�Χ�����ϵ����ͬ�����±���
|
�� �� |
�� ͬ �� |
�� �� �� �� �� |
�� �� �� ϵ |
�� �� �� Χ |
|
��������� |
����������ÿ�����屻��ȡ�ĸ������ |
�������������ȡ |
|
�����еĸ��������� |
|
ϵͳ���� |
��������ֳɼ������֣�Ȼ��������ȷ���Ĺ����ڸ����ֳ�ȡ |
����ʼ���ֳ���ʱ���ü�������� |
�����еĸ������϶� |
|
|
�ֲ���� |
������ֳɼ��㣬�ֲ���г�ȡ |
�������ʱ���ü�������� |
�����ɲ������Եļ�������� |
������������������
1. ������������������������
��1��ƽ����![]() ��
��![]()
��2������![]() ��
��![]()
��3������ ����һ�������У����ִ����������ݡ�
��4����λ������һ�����ݰ���С�������У��������м��һ�����ݣ����������ݵ�ƽ������
ע����һ��n�����ݣ�![]() ����ƽ����Ϊ
����ƽ����Ϊ![]() ������Ϊ
������Ϊ![]() ������n�����ݽ��б任��
������n�����ݽ��б任��
��![]() ���õ�һ�������ݣ�
���õ�һ�������ݣ�![]() ���������ݵ�ƽ����������ֱ���
���������ݵ�ƽ����������ֱ���![]() �����У�
������![]()
2. ͳ��ͼ��
��1����Ҷͼ
�������������λ��Ч����ʱ�����м�����ֱ�ʾʮλ��������һ����Ч���֣����ߵ����ֱ�ʾ��λ�������ڶ�����Ч���֣������м䲿����ֲ��ľ������߲�����ֲ�ᆬ�ϳ�������Ҷ�ӣ����ͨ����������ͼ������Ҷͼ��
��Ҷͼ��������
��a���þ�Ҷͼ��ʾ�����������ŵ㣺һ��ͳ��ͼ��û��ԭʼ������Ϣ����ʧ������������Ϣ�����ԴӾ�Ҷͼ�еõ������Ǿ�Ҷͼ�е����ݿ�����ʱ��¼����ʱ���ӣ������¼���ʾ��
��b����Ҷͼֻ���ڱ�ʾ��λ����һλ����Ч���ֵ����ݣ����Ҿ�Ҷͼֻ�����¼��������ݣ��������ϵ�������ȻҲ�ܹ���¼����û�б�ʾ������¼��ôֱ��������������Ҷͼ�ķ�������������λ����ʮλ������Ϊ����������λ������ΪҶ������ͬ�߹���һ������������С�����˳����������г���������Ҷһ�㰴�Ӵ�С�����С����˳��ͬ���г���
ע����ͬ������Ҫ�ظ���¼��������©��
��2��Ƶ�ʷֲ�ֱ��ͼ
��a�����壺ÿ��С���εĿ�����![]() ��������ȣ�����Ϊ
��������ȣ�����Ϊ![]() ��С���ε��������Ӧ��Ƶ�ʣ�������ͼ�ν�Ƶ�ʷֲ�ֱ��ͼ������ͼ����
��С���ε��������Ӧ��Ƶ�ʣ�������ͼ�ν�Ƶ�ʷֲ�ֱ��ͼ������ͼ����
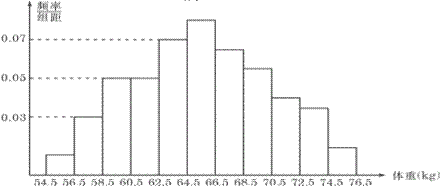
��b��������Ƶ�ʷֲ�ֱ��ͼ�IJ��裺
���
�ھ������������������������/��ࣩ��
�۽����ݷ��飻
����Ƶ�ʷֲ��������飬Ƶ����Ƶ�ʣ���
�ݻ�Ƶ�ʷֲ�ֱ��ͼ��
ע��Ƶ�ʷֲ�ֱ��ͼ��������
��i����Ƶ�ʷֲ�ֱ��ͼ��������ؿ������ݷֲ����������ơ�
��ii����Ƶ�ʷֲ�ֱ��ͼ�ò���ԭʼ���������ݣ������ݱ�ʾ��ֱ��ͼ��ԭ�еľ���������Ϣ�ͱ�Ĩ���ˡ�
����������أ���С���˷������Իع鷽�̣����ع�����������Լ���
1. ����Ե��йظ�����
������ϣ�������֮�����ij�ֹ�ϵ����Щ�����һ�����еĴ������ƣ���������ͨ������һ���⻬�����������ƣ������Ľ��ƹ��̽�������ϡ�
������أ�������������ɢ��ͼ�У����еĵ㿴��ȥ����һ��ֱ�߸�����������Ʊ�������������صģ���ʱ����һ��ֱ�߽��ơ�
��������أ�������������ɢ��ͼ�У����еĵ㿴��ȥ����һ�����߸�����������Ʊ������Ƿ�������صģ���ʱ����һ�����߽��ơ�
����أ����еĵ���ɢ��ͼ��û���κι�ϵ�����������������ء�
ע����ع�ϵ�뺯����ϵ��ͬ��������ϵ�е�������������һ��ȷ���Թ�ϵ����ع�ϵ��һ�ַ�ȷ���Թ�ϵ������ع�ϵ�Ƿ�����������������֮��Ĺ�ϵ��
2. ��С���˷�
��1����С���˷��Ķ��塣
��2�����Իع鷽�̣���x��y�Ǿ�����ع�ϵ����������������Ӧ��n���۲�ֵ��n������·ֲ���ijһ��ֱ�ߵĸ������Ϳ�����Ϊy��x�Ļع麯��������Ϊֱ���ͣ�![]() ������
������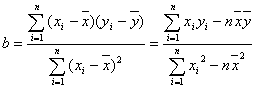 ��
��![]() �����dz��������Ϊ���Իع����̡�
�����dz��������Ϊ���Իع����̡�
3. �ع������
��1�����壺�Ծ�����ع�ϵ��������������ͳ�Ʒ�������
��2�����ϵ����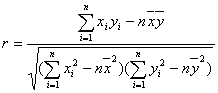 ����r��ֵ��r>0������������أ�r<0������������ء�|r|Խ�ӽ�1�������������������Խǿ��|r|Խ�ӽ����������������������������ء�ͨ����Ϊ��|r|>0.75ʱ�����������к�ǿ������ԡ�
����r��ֵ��r>0������������أ�r<0������������ء�|r|Խ�ӽ�1�������������������Խǿ��|r|Խ�ӽ����������������������������ء�ͨ����Ϊ��|r|>0.75ʱ�����������к�ǿ������ԡ�
�����㷨���ͼ���й�֪ʶ
1. �㷨�ĸ���㷨��ָ�����ü�����������ijһ������ij�����裬��Щ��������������ȷ�ĺ���Ч�ģ������ܹ�������֮����ɡ�
2. �����ͼ����Ҫ�ɳ�������������ɡ�
�㷨���������ṹ��˳��ṹ�������ṹ��ѭ���ṹ
��1��˳��ṹ����ָ��һ���㷨�������ǰ���������ִ�еģ�����һ������㷨�ṹ��Ҳ���κ�һ���㷨�ز����ٵ����ṹ��
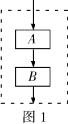
��2�������ṹ����ָ���㷨����ʱҪ�����жϣ��жϵĽ��ֱ�Ӿ��������ִ�в��衣
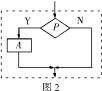
��3��ѭ���ṹ����ij����ʼ������һ������������ִ��ijһ�������裬���з���ִ�д��������Ϊѭ���塣
ע��ѭ���ṹ����Ҫ��:ѭ��������ѭ���壬ѭ������ֹ������
3. �������
��1����ֵ���
������2���������
��3��������
��4��������䣺
һ���ʽ�ǣ�

������5��ѭ�����
WHILEѭ���ĸ�ʽΪ��

UNTILѭ���ĸ�ʽΪ��

��������
֪ʶ��һ��ͳ�Ƶ��й�֪ʶ
��1. ������������
���μ�����Ӫ��600��ѧ�����Ϊ��001��002������600������ϵͳ����������ȡһ������Ϊ50���������������õĺ���Ϊ003����600��ѧ����ס������Ӫ������001��300�ڵڢ�Ӫ������301��495�ڵڢ�Ӫ������496��600�ڵڢ�Ӫ��������Ӫ�������е���������Ϊ�� ��
A. 26, 16, 8 B. 25��17��8
C. 25��16��9 D. 24��17��8
��˼·��������������Ҫ��������ķ�����
���⿼���е�������Ⱦ�������ķ������״���������г�ȡ�ĺ�����003,�Ժ�ÿ��12����ȡһ�ˣ���ֱ��ǣ�003��015��027������������3Ϊ���12Ϊ����ĵȲ����С�
��������̡�����֪���״���������г�ȡ�ĺ�����003,�Ժ�ÿ��12����ȡһ�ˣ���ֱ��ǣ�![]() ������3Ϊ���12Ϊ����ĵȲ����С����ڵ�IӪ����ȡ��������n����
������3Ϊ���12Ϊ����ĵȲ����С����ڵ�IӪ����ȡ��������n����![]() ������ȡ25�ˣ�ͬ�������ڵ�II��IIIӪ���ֱ��ȡ17�ˡ�8�ˡ�ѡB��
������ȡ25�ˣ�ͬ�������ڵ�II��IIIӪ���ֱ��ȡ17�ˡ�8�ˡ�ѡB��
��������˼���������������Ĺؼ������շֲ��������е�������Ⱦ�������ķ��������������ڷֲ�����У�ÿ���ȡ��������![]() ��n������������N�����������
��n������������N�����������![]() ��ʾ��i��ĸ������������ڵȾ�����У���ȡ�ı���ǣ���ʼ���+�����ࣨ��������������Ϸ����ɷ�����⡣
��ʾ��i��ĸ������������ڵȾ�����У���ȡ�ı���ǣ���ʼ���+�����ࣨ��������������Ϸ����ɷ�����⡣
��2. �����ݵ�����������
�����ȡij��ѧ�ס��������10��ͬѧ,�������ǵ����ߣ���λ:cm��,����������ݵľ�Ҷͼ����ͼ��
��1�����ݾ�Ҷͼ�ж��ĸ����ƽ�����߽ϸߣ�
��2������װ���������
��3���ִ��Ұ���10��ͬѧ�������ȡ�������߲�����173cm��ͬѧ,������Ϊ176cm��ͬѧ�����еĸ��ʡ�
��˼·����������ͨ����Ҷͼ��¼���ݣ��������ݲ�����ƽ�����ͷ��
��1�����ݾ�Ҷͼ��֪�ס��ҡ�����ѧ�������������ƴӶ������жϡ�
��2�����������ʽ���㣬����![]() ������
������![]() ��
��
��3�����ùŵ���ʹ�ʽ��⡣
��������̡�
��1���ɾ�Ҷͼ��֪���װ�ѧ����������![]() �M֮�䣬���Ұ�ѧ����������
�M֮�䣬���Ұ�ѧ����������![]() �M֮�䡣����Ұ�ƽ�����߸��ڼװ�;
�M֮�䡣����Ұ�ƽ�����߸��ڼװ�;
��2��![]()
�װ����������Ϊ
![]()
![]() ��57
��57
��3��������Ϊ176cm��ͬѧ�����е��¼�ΪA�����Ұ�10��ͬѧ�г����������߲�����173cm��ͬѧ�У���181��173�� ��181��176�� ��181��178�� ��181��179�� ��179��173�� ��179��176�� ��179��178�� ��178��173�� ��178,
176�� ��176��173����10�������¼������¼�A����4�������¼���
![]()
��������˼�����ӽ������¿α�߿�����������������Ҷͼ�������������ʵ������Ϊ��Ҫ���ⷽ��ͨ��Ҷ��ͼ��������������λ����ƽ����������ȣ�ͨ����������λ����ƽ�����������ݵļ������ƣ�ͨ����������������ݵIJ����ԡ�ͬʱҪ����ƽ����������ļ��㷽���ͼ��ɡ�
��3. �������������壩
ijʳƷ��Ϊ�˼��һ���Զ���װ��ˮ�ߵ���������������ȡ����ˮ����40����Ʒ��Ϊ����������ǵ���������λ���ˣ������ķ�������Ϊ��490,495������495,500����������510,515�ݣ��ɴ˵õ�������Ƶ�ʷֲ�ֱ��ͼ����ͼ��ʾ��
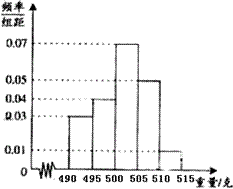 ]
]
��1������Ƶ�ʷֲ�ֱ��ͼ������������505�˵IJ�Ʒ������
��2����������ȡ��40����Ʒ����ȡ2������YΪ��������505�˵IJ�Ʒ��������Y�ķֲ�����
��3������ˮ������ȡ5����Ʒ����ǡ��2����Ʒ�ϸ����������505�˵ĸ�����
��˼·������
��1������ֱ��ͼ��������ÿ���ڲ�Ʒ������=![]() ��
��
��2��ȷ����ɢ���������Y��ȡֵ���������֪ʶ��Y��ȡֵ��Ӧ�ĸ��ʡ�
��3�������¼���������![]() ����ǡ��2����Ʒ�ϸ����������505�ˡ��������¼����ǣ�
����ǡ��2����Ʒ�ϸ����������505�ˡ��������¼����ǣ�![]() ��
��
��������̡���1����������505�˵IJ�Ʒ������
40����0.05��5+0.01��5��=40��0.3=12����
��2��Y�ķֲ���Ϊ
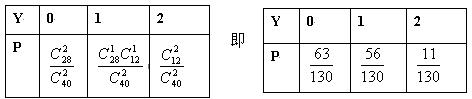
��3������ˮ������ȡ5����Ʒ����ǡ��2����Ʒ�ϸ����������505�˵ĸ�����
P=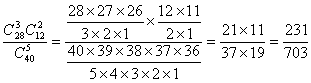 ��
��
��������˼�������������������֪ʶ��Ŀ�����Ҫ��Ƶ�ʷֲ�ֱ��ͼΪ����Ҫ��ʶֱ��ͼ���������磺Ƶ��=![]() ����С���Ƶ��֮����1��ֱ��ͼ�еĸ�С���ε������ʾ��Ӧ�ĸ���С���Ƶ�ʵȡ�
����С���Ƶ��֮����1��ֱ��ͼ�еĸ�С���ε������ʾ��Ӧ�ĸ���С���Ƶ�ʵȡ�
��4. ��������أ�
�±��ṩ��ij�����ܽ��ļ�������������ײ�Ʒ�����м�¼�IJ���![]() ���֣�����Ӧ�������ܺ�
���֣�����Ӧ�������ܺ�![]() ���ֱ�ú���ļ����������
���ֱ�ú���ļ����������
|
|
|
|
|
|
|
|
|
|
|
|
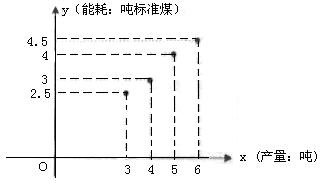
��1���뻭���ϱ����ݵ�ɢ��ͼ��
��2��������ϱ��ṩ�����ݣ�����С���˷����![]() ����
����![]() �����Իع鷽��
�����Իع鷽��![]() ��
��
��3����֪�ó�����ǰ100�ּײ�Ʒ�������ܺ�Ϊ90�ֱ�ú��
�Ը�����������Իع鷽�̣�Ԥ������100�ּײ�Ʒ�������ܺıȼ���ǰ���Ͷ��ٶֱ�ú?
���ο���ֵ��![]() ��
��
��˼·������
��1��������֪���е����ݣ�����ɢ��ͼ��
��2������ɢ��ͼ�ж����������Ƿ�������أ������������Իع鷽�̡�
��3���������Իع鷽����x=100ʱ���ܺ�y��ֵ��
��������̡�
��1��ɢ��ͼ��ͼ��ʾ��
��2���ɶ������ݣ�����ã�
![]() ��
��![]() ��
��![]() ��
��![]()
![]()
����Ļع鷽��Ϊ![]()
��3��![]() ��
��![]() ���ֱ�ú��
���ֱ�ú��
Ԥ������100�ּײ�Ʒ�������ܺıȼ���ǰ����![]() ���ֱ�ú��
���ֱ�ú��
��������˼�������¿α�߿�����ķ�������������ʵ��Ӧ������ij��ֻ������ֻ࣬Ҫ���մ�����������Ļ����������ɣ���Ŀ�Ѷ�С��
֪ʶ������㷨���ͼ
��5. ��ѭ���ṹ��
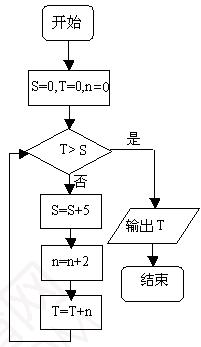
1. ִ�г����ͼ����ͼ���������T=_________��
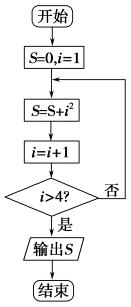
2. �Ķ���ͼ�ij����ͼ���������S��______________��
��˼·������
1. ������һ��ѭ���ṹ����T��Sʱ����ѭ������T>Sʱ����ѭ�������տ�ͼ����д��S��n��T��ֵ����T>Sʱ�����T,�������T��ֵ��
2. ����ѭ���壺S=S+i2��S��i�ij�ʼֵ���㣬��![]() ʱ����ѭ����
ʱ����ѭ����
��������̡�
1. �����ͼ����ִ��:��һ����S=5,n=2,T=2��
�ڶ�����
S=10,n=4,T=2+4=6��
��������S=15,n=6,T=6+6=12��
���IJ���S=20,n=8,T=12+8=20��
���岽��S=25,n=10,T=20+10=30>S,���T=30��
2. S��1��4��9��16��30��
��������˼����������Ҫ������ѭ���ṹ�ij����ͼ,Ҫ�������ֵҪץס��������Ҫ�أ���1��ѭ�������ij�ʼֵ����2��ѭ���壬��3��ѭ����������ֹ������һ�㶼�ɷ�����������ֱ��������������,�������漰����������,ע��ÿ�����������н����ִ�������
��6. ����ȫ��ͼ��
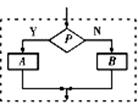
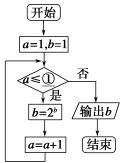
1. ִ����ͼ��ʾ�ij����ͼ���������b��ֵΪ16����ͼ���жϿ�������Ӧ�������
A. 3 B. 4
C. 5 D. 2
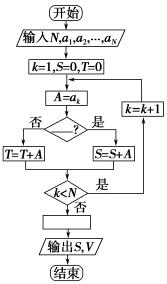
2. ij��һ���µ������֧���ܹ���¼��N�����ݣ�a1��a2������aN�����������Ϊ������֧����Ϊ�������õ����±ߵij����ͼ������������S���¾�ӯ��V.��ô��ͼ�пհ��жϿ�ʹ������У�Ӧ�ֱ����������ĸ�ѡ���еģ�������
A. A��0��V��S��T
B. A��0��V��S��T
C. A��0��V��S��T
D. A��0��V��S��T
��˼·������
1. ����ѭ�������ÿ��ѭ�����b��ֵ��a��ֵ�����õ�b=16���ɵ�a��ֵ���ٸ���a��ֵд��ѭ����ֹ������
2. ������һ�������ṹ����һ���жϿ��ж�![]() �����뻹��֧�����ڶ����жϿ��ж���N�������Ƿ�������ϣ���������������S���¾�ӯ��V����������SӦ��Ϊ���µĸ�������֮�ͣ��¾�ӯ��VӦ��Ϊ��������S��ȥ���µĸ���֧��֮�͵��������ɴ��ж�ѡ�
�����뻹��֧�����ڶ����жϿ��ж���N�������Ƿ�������ϣ���������������S���¾�ӯ��V����������SӦ��Ϊ���µĸ�������֮�ͣ��¾�ӯ��VӦ��Ϊ��������S��ȥ���µĸ���֧��֮�͵��������ɴ��ж�ѡ�
��������̡�
1. ���ճ����ͼ����ִ�У���ʼa��1��b��1����һ��ѭ����b��21��2��a��1��1��2���ڶ���ѭ����b��22��4��a��2��1��3��������ѭ����b��24��16��a��3��1��4������ʱӦ���b��ֵ�����жϿ��е�����ӦΪa��3����ѡA��
2. ��������SӦ��Ϊ���µĸ�������֮�ͣ���������A��0���¾�ӯ��VӦ��Ϊ��������S��ȥ���µĸ���֧��֮�ͣ���ΪT��0����V��S��T����ѡC��
��������˼������ȫ��ͼ�������¿α�߿����ص�����֮һ������Ĺؼ�����ʶ��ͼ�����ṹ�������ĺ��塣
��7. ���㷨�ۺϣ�
��֪�Ȳ�����{an}�ĸ����Ϊ�������۲�����ͼ����![]() ʱ���ֱ���
ʱ���ֱ���![]() ��
��
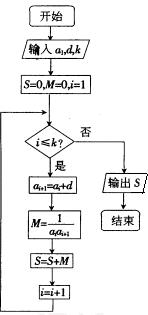
��1����������{an}��ͨ�
��2����![]() ��ֵ��
��ֵ��
��˼·������
��a��������֪�Ŀ�ͼ�ã�![]() ��
��
��b���ٸ��������ǵȲ����У�����֪�������������
��c���ɵȱ��������ʽ��͡�
��������̡�
�ɿ�ͼ��֪![]() ��
��![]()
����![]()
![]()
��1���������֪��k=5ʱ��![]()
 ����
����![]()
��2���ɣ�1���ɵã�![]()
![]()
��������˼�����㷨������ͳ�ơ����ʡ�������֪ʶ��������ϵ������������Щ��ͳ֪ʶ��Ŀ��飬������������ûʲô���⣬�����㷨�����������˶�Ŀһ�£������������㷨���ֽ�����������ݵĿ��顣�����¿α�߿�����ķ���
��ּ���
�¿α�߿�����ͳ��֪ʶ�Ի���֪ʶΪ����������Ѷ�С��ֻҪ����ͳ���еĻ���֪ʶ���ܽ�����ڿ����㷨���ͼ��֪ʶ���У�Ҫ��ͣ���Ŀ�Ѷ�С��ֻҪ���Ⲣ�����������ṹ���ɣ��������Ѷȹ�����⣬����Ļ����϶��ǶԿ�ͼ����ʶ����Ӧ�ã���Խϸ��ӵ���ѭ���ṹ������ѭ���ṹ�������ǽ������Ĺؼ���
Ԥϰ��ѧ
һ��Ԥϰ��֪
1. ������������������ɵģ��Ծ�һ����
2. ���������֮�֣��Ծ�һ�������⣬һ�������⡣
3. ��![]() ��������������������˵�����ɡ�
��������������������˵�����ɡ�
����Ԥϰ�㲦
1. ��һ���������Ϊ����p,��q��������������ɱ���Ϊ________���������ɱ���Ϊ_______�����������ɱ���Ϊ____________________��
2. �����⡰��p����q��Ϊ�����⣬��p��q��_____________������ͬʱq��p��
__________���������������������Ҳ�������⣬��p��q��Ϊ____________������
3. ___________________��ȫ�����ʣ�__________________________________��ȫ�����⡣
_____________________���س����ʣ�_________________________________���س����⡣
��1��������ʱ��Ҫע��ؼ��ʵķ�����д�±����ؼ��ʵķ�
|
�ؼ��� |
�� |
�ؼ��� |
�� |
�ؼ��� |
�� |
�ؼ��� |
�� |
|
����һ�� |
|
���� |
|
������ |
����һ�� |
һ����û�� |
|
��2����д�±�������������ȫ�����⣬��д��Ӧ�Ĵ������⡣
|
���� |
ȫ������ |
�������� |
|
�������� |
1. ���е�x 2. ��һ�е�x 3. ��ÿһ��x 4. �����һ��x 5. ��x |
1. ____________________ 2. ____________________ 3. ____________________ 4. ____________________ 5. ____________________ |
4. _______________________________________________________________��������ʡ��������⡱������ж��ܽ�Ϊ��һ��Ϊ�棬ͬ��Ϊ�١��������⡱������ж��ܽ�Ϊ��һ��Ϊ�٣�ͬ��Ϊ�档�������⡱������ж��ܽ�Ϊ��ԭ���Ϊ�٣�ԭ�ٷ�Ϊ�档
ͬ����ϰ������ʱ�䣺60���ӣ�
һ��ѡ���⣺
1. ij��λ�����ϡ��С���ְ��430��,��������ְ��160�ˣ�����ְ������������ְ��������2����Ϊ�˽�ְ������״�����ֲ��÷ֲ�����������е��飬�ڳ�ȡ��������������ְ��32�ˣ���������е�����ְ������Ϊ
A.
9
B. 18
C. 27
D. 36
2. һ������Ϊ100�������������ݵķ���������Ƶ�����±�
|
��� |
|
|
|
|
|
|
|
|
Ƶ�� |
12 |
13 |
24 |
15 |
16 |
13 |
7 |
���������������ϵ�Ƶ��Ϊ��10,40![]() �ϵ�Ƶ��Ϊ
�ϵ�Ƶ��Ϊ
A. 0.13 B. 0.39 C. 0.52 D. 0.64
3. �ڷ���ij���������¼��ڼ䣬��רҵ������Ϊ���¼���һ��ʱ��û�з������ģȺ���Ⱦ�ı�־Ϊ������10�죬ÿ���������Ʋ���������7�ˡ������ݹ�ȥ10��ס��ҡ��������ĵ��������Ʋ������ݣ�һ�����ϸñ�־����
A. �أ������ֵΪ3����λ��Ϊ4 B. �ҵأ������ֵΪ1�����巽�����0
C. ���أ���λ��Ϊ2������Ϊ3
D. ���أ������ֵΪ2�����巽��Ϊ3
4. ��ͼ������A��B�ֱ�ȡ��������ͬ�����壬���ǵ�����ƽ�����ֱ�Ϊ![]() ����������ֱ�ΪsA��sB���� ��
����������ֱ�ΪsA��sB���� ��
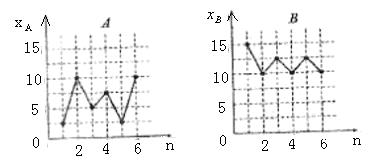
A. ![]() ��
��![]() ��sA��sB
��sA��sB
B. ![]() ��
��![]() ��sA��sB
��sA��sB
C. ![]() ��
��![]() ��sA��sB
��sA��sB
D. ![]() ��
��![]() ��sA��sB
��sA��sB
5. ���ִ����ͼ�ij����ͼ������![]() ����ô����ĸ������ĺ͵��ڣ� ��
����ô����ĸ������ĺ͵��ڣ� ��
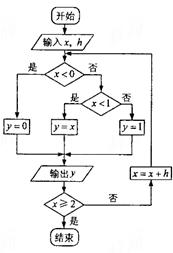
A.3 B.3.5 C.4 D.4.5
6. ij�����ͼ��ͼ��ʾ���������S=57�����жϿ���Ϊ ��
��
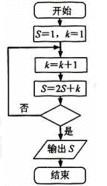
A. k��4?
B. k��5?
C. k��6?
D. k��7?
7. �Ķ��±ߵij����ͼ��������Ӧ�ij��������s��ֵΪ�� ��
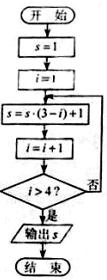
A. 1 B.
0 C. 1 D. 3
8. ���ִ������ij����ͼ������n=6,m=4����ô�����P����
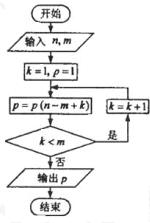
A. 720
B. 360
C. 240
D. 120
��������⣺
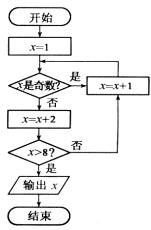
9. ��ͼ��ʾ�������ͼ���㷨����ͼ�������ֵx=
10. ij��λ200��ְ��������ֲ������ͼ����Ҫ���г�ȡ40��ְ������������ϵͳ����������ȫ��ְ�������1��200��ţ��������˳��ƽ����Ϊ40�飨1��5�ţ�6��10�š���196��200�ţ�������5�����ĺ���Ϊ22�����8�����ĺ���Ӧ�� �����÷ֲ������������40�����������Ӧ��ȡ �ˡ�
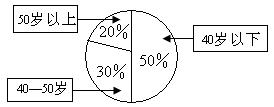
11. ��ͼ����������Ϊ200��Ƶ�ʷֲ�ֱ��ͼ������������Ƶ�ʷֲ�ֱ��ͼ���ƣ�������������[6��10]�ڵ�Ƶ��Ϊ
���������ڣ�2��10���ڵĸ���ԼΪ
�� ![]()
![]()
����������
12.
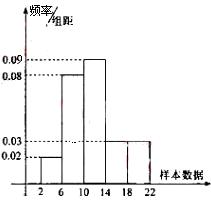
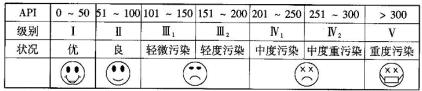
���ݿ�������ָ��API��Ϊ�������IJ�ͬ���ɽ����������ּ����±���
��ij����һ�꣨365�죩�Ŀ����������м�⣬��õ�API���ݰ�������![]() ��
��![]() ��
��![]() ��
��![]() ��
��![]() ��
��![]() ���з��飬�õ�Ƶ�ʷֲ�ֱ��ͼ��ͼ
���з��飬�õ�Ƶ�ʷֲ�ֱ��ͼ��ͼ

��1����ֱ��ͼ��![]() ��ֵ��
��ֵ��
��2������һ���п��������ֱ�Ϊ��������Ⱦ��������
��3����ó���ijһ��������2��Ŀ�������Ϊ��������Ⱦ�ĸ��ʡ�
������÷�����ʾ����֪![]() ��
��![]() ��
��![]()
![]()
![]() ��
��![]() ��
��
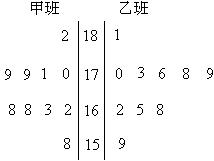
13. ij��������������������һ��С����Ʒ��A��������ԭ�е�һ������Ʒ��B���ж���
���飬����С�����ֲ��25Ķ������Ķ�����ݣ���λ��ǧ�ˣ����£�. ![]()
![]()
Ʒ��A��357��359��367��368��375��388��392��399��400��405��412��414��
415��421��423��423��427��430��430��434��443��445��445��451��454
Ʒ��B��363��371��374��383��385��386��391��392��394��394��395��397��
397��400��401��401��403��406��407��410��412��415��416��422��430
��1����������ľ�Ҷͼ
��2���þ�Ҷͼ�������е����ݣ���ʲô�ŵ㣿. ![]()
![]()
��3��ͨ���۲쾥Ҷͼ����Ʒ��A��B��Ķ���������ȶ��Խ��бȽϣ�д��ͳ�ƽ��ۡ�
![]()
�����
һ��ѡ���⣺
1. B ����:�ɱ����ɵøõ�λ����ְ������90�ˣ��÷ֲ�����ı���Ӧ��ȡ18�ˡ���ѡB��
2. C ���� �������֪Ƶ����![]() �ϵ��У�13+24+15=52����Ƶ��=Ƶ��
�ϵ��У�13+24+15=52����Ƶ��=Ƶ��![]() �����ɵ�0.52.��ѡC��
�����ɵ�0.52.��ѡC��
3. C ������������Ϣ��֪������10���ڣ�ÿ����������Ʋ��������г���7������ѡ��A�У���λ��Ϊ4�����ܴ��ڴ���7������ͬ������ѡ��C��Ҳ�п��ܣ�ѡ��B�е����巽�����0����������ȷ�������Ŀ̫��Ҳ�п��ܴ��ڴ���7������ѡ��D�У����ݷ��ʽ������д���7�������ڣ���ô�����Ϊ3����ѡD��
4. B ������![]() ��10��
��10��![]() ��A��ȡֵ�����̶���Ȼ����B������sA��sB����ѡB��
��A��ȡֵ�����̶���Ȼ����B������sA��sB����ѡB��
5. B
��������1����y��0��x����1.5����2����y��0��x����1����3����y��0��x����0.5��
��4����y��0��x��0����5����y��0��x��0.5����6����y��0.5��x��1����7����y��1��x��1.5����8����y��1��x��2����9����y��1���˳�ѭ���������֮��Ϊ��0.5��1��1��1��3.5����ѡB��
6. A
7. B ��������һ�����г���ʱi=1��s=3���ڶ������г���ʱ��i=2��s=2�����������г���ʱ��i=3��s=1�����Ĵ����г���ʱ��i=4��s=0����ʱִ��i=i+1��i=5���˳�ѭ�����s=0��
8. B ������![]() ѡB��
ѡB��
���������
9. 12 �����������������£�
![]() ,���12��
,���12��
10. 37��20 �������ɷ����֪,��ŵļ��Ϊ5,����Ϊ��5�����ĺ���Ϊ22�����Ե�6�����ĺ���Ϊ27����7�����ĺ���Ϊ32����8�����ĺ���Ϊ37��40����������ε�ְ����Ϊ![]() ,��Ӧ��ȡ������Ϊ
,��Ӧ��ȡ������Ϊ![]() �ˡ�
�ˡ�
11. 64,��0.4 �������۲�ֱ��ͼ��Ƶ��Ϊ200��0.08��4=64��Ƶ��Ϊ0.1��4=0.4
���������⣺
12. �⣺��1����ͼ��֪![]()
![]()
![]()
![]() �����
�����![]() ��
��
��2��![]() ���죩��
���죩��
��3���ó���һ����ÿ���������Ϊ��������Ⱦ�ĸ���Ϊ![]() ��������������Ϊ���Ҳ�Ϊ����Ⱦ�ĸ���Ϊ
��������������Ϊ���Ҳ�Ϊ����Ⱦ�ĸ���Ϊ![]() ��һ��������2����������Ϊ��������Ⱦ�ĸ���Ϊ
��һ��������2����������Ϊ��������Ⱦ�ĸ���Ϊ![]() ��
��
13. ��������1����Ҷͼ��ͼ��ʾ
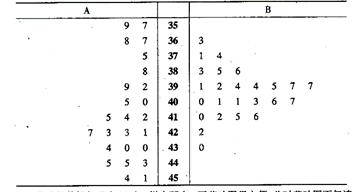
��2���þ�Ҷͼ�������е����ݲ������Կ������ݵķֲ�״��,���ҿ��Կ���ÿ���еľ�������.
��3��ͨ���۲쾥Ҷͼ�����Է���Ʒ��A��ƽ��Ķ����Ϊ411.1ǧ�ˣ�Ʒ��B��ƽ��Ķ����Ϊ397.8ǧ��.�ɴ˿�֪��Ʒ��A��ƽ��Ķ������Ʒ��B��ƽ��Ķ�����ߡ���Ʒ��A��Ķ���������ȶ�����Ʒ��B��Ķ�����Ƚϼ��У���ƽ������������